健心知著
2025.11.26
第513期

智能视图分析AI实现超声心动图全方位评估

刘健、周海燕、孙宇彤
北京大学人民医院
健心荐语
超声心动图作为临床应用最广泛的心脏影像学检查手段,其准确评估对心血管疾病诊疗具有关键意义。然而传统超声心动图分析高度依赖医师经验,存在主观性强、不同观察者间差异大等局限性。近年来人工智能技术在医学影像分析领域取得显著进展,但现有超声心动图AI模型多局限于单一视图、单一任务的分析模式,未能有效整合完整检查中多视图视频信息的互补价值,导致模型性能和应用范围受到严重制约。尽管已有研究尝试构建基础模型,但其大多基于静态图像分析,未能充分利用超声视频的时序动态信息,更缺乏对多视图信息的有效融合机制。这种技术局限使得现有AI模型难以实现真正符合临床实践需求的全面心脏评估。本文旨在开发一个能融合多视图视频信息的新型视觉语言基础模型EchoPrime,通过引入解剖注意力机制实现全面智能评估,突破现有技术瓶颈。
文章介绍
本研究是一项基于大规模、多中心数据的超声心动图人工智能研究。该研究旨在开发新型视觉语言基础模型EchoPrime,通过整合多视图视频信息实现全面心脏评估。研究采用超过1200万视频-报告对进行模型训练,并创新性地引入解剖注意力机制实现多视图信息融合,其主要终点为在五个国际医疗中心数据集上的23项心脏结构与功能评估性能。本文首次实现了多视图视频信息的智能整合与加权评估,为超声心动图自动化分析开辟了新途径。该研究于2025年11月正式发表于国际顶级期刊《Nature》。
研究方法
本研究构建了规模空前的多中心超声心动图数据集,核心训练集包含来自Cedars-Sinai医学中心的12,124,168个超声视频,对应275,442次检查的108,913例患者,时间跨度为2011年至2022年。所有数据均经过严格的标准化预处理:原始DICOM文件统一转换为AVI格式,进行完整的去标识化处理,保留关键超声影像区域,并调整为224×224像素的标准尺寸。数据集按患者级别严格划分为训练集(107,663例患者)、验证集(250例患者)和测试集(1,000例患者),确保数据完全独立。外部验证集涵盖四个国际医疗中心,包括Stanford Healthcare(1,792次检查)、MIMIC-IV(2,431次检查)、Chang Gung Memorial Hospital(1,188次检查)和Kaiser Permanente(4,891次检查),所有外部数据均采用相同预处理流程以保证一致性。
EchoPrime采用创新的多模块架构:视频编码器基于Kinetics预训练的多尺度视觉变换器(mVIT),处理224×224×16×3的输入张量,输出512维视频嵌入;文本编码器使用PubMedBERT模型,最大上下文长度512个token,通过全连接层输出512维文本嵌入;视图分类器基于ConvNextBase架构,在77,426个专业标注视频上训练,可准确识别58个标准超声切面(AUC 0.997);解剖注意力模块采用深度多实例学习框架,将视图分类结果与视频嵌入拼接,学习不同切面对特定解剖结构的评估权重,实现多视频信息的智能融合。
训练过程采用分阶段策略:对比学习预训练使用32批次视频-报告对,通过可学习温度参数缩放相似度矩阵,计算交叉熵损失,同时冻结文本编码器前6层以保留医学先验知识;精细调优阶段在清洗后的数据集上训练20个epoch,修正报告错误并排除特殊检查类型;解剖注意力训练通过多层感知机网络学习15个解剖部位的切面重要性权重。优化使用AdamW优化器,初始学习率4×10-⁵,权重衰减1×10-⁶,配合ReduceOnPlateau学习率调度,在两个NVIDIA RTX A6000 GPU上采用分布式数据并行训练。内部测试使用完全保留的2,621次检查,外部验证涵盖四个国际医疗中心的独立数据集。评估体系包含23个临床任务,分类任务采用AUROC和平衡准确度,回归任务使用R²和MAE。统计采用10,000次bootstrap抽样计算95%置信区间,DeLong检验评估显著性。专项测试包括:低质量图像环境验证鲁棒性;单视图设置(2,172次仅含A4C视图的研究)测试受限条件性能;医生间变异度分析评估临床一致性;迁移学习实验通过线性探测和K近邻算法验证对心脏淀粉样变性和STEMI的识别能力,全面考察模型临床价值。
研究结果
本研究在模型性能验证方面取得了显著成果,在来自五个国际医疗中心的大规模数据集上进行了全面评估。在Cedars-Sinai医学中心内部测试集上,EchoPrime在左心室射血分数评估这一核心指标上实现了4.79%的平均绝对误差(95% CI: 4.60-4.97),这一精度显著超越了对比模型BioMedCLIP(26.93)和EchoCLIP(7.00)。在外部验证中,该指标在Stanford Healthcare达到4.14%(3.94-4.34),在MIMIC数据集为6.21%(5.54-6.92),在Chang Gung Memorial Hospital为6.46%(6.19-6.74),在Kaiser Permanente为4.51%(4.30-4.72),展现出卓越的泛化能力。在疾病诊断性能方面,模型在主动脉瓣反流检测任务中表现突出,在内部测试集AUC达到0.88(0.83-0.93),外部验证中Stanford Healthcare为0.89(0.80-0.97),MIMIC为0.81(0.75-0.86),CGMH为0.78(0.70-0.84),KP为0.87(0.83-0.92)。其他关键指标包括:三尖瓣反流检测AUC在0.84-0.95之间,心包积液诊断AUC在0.87-0.98之间,主动脉瓣狭窄检测AUC在0.88-0.99之间。特别值得关注的是,模型在跨模态检索任务中实现了98%的视频-文本检索召回率,较EchoCLIP提升45个百分点;在文本-视频检索任务中达到97%的召回率,提升35个百分点。在视图分类任务中,模型在58个标准切面的识别上达到0.997的AUC,为后续的解剖注意力加权提供了可靠基础。在临床实用性评估中,EchoPrime与心脏科医生的诊断一致性(平衡准确度0.89)超过了医生间自身的一致性(平衡准确度0.82)。在技术困难病例和单视图受限条件下,模型仍保持稳健性能,其左心室射血分数评估的R²在单视图设置下仅从0.83降至0.78。此外,模型展现出卓越的迁移学习能力,在未经过专门训练的情况下,通过K近邻算法就能以0.92的AUC识别ST段抬高型心肌梗死,以0.96的AUC诊断心脏淀粉样变性,这一表现超越了专门的诊断模型。所有结果的统计学显著性均经过严格验证,使用10,000次bootstrap抽样计算置信区间,关键指标的p值均小于0.05,证明了模型性能提升的可靠性。这些结果充分展示了EchoPrime在真实临床环境中的实用价值和推广潜力。

表1:Clinical characteristics of the study cohorts

表2:EchoPrime 超声心动图解读性能横跨来自 5 个不同医疗中心的 406 个数据集。对于分类任务,我们报告 AUROC;对于回归任务,我们使用 R2 和均方误差 (MAE) 进行评估。
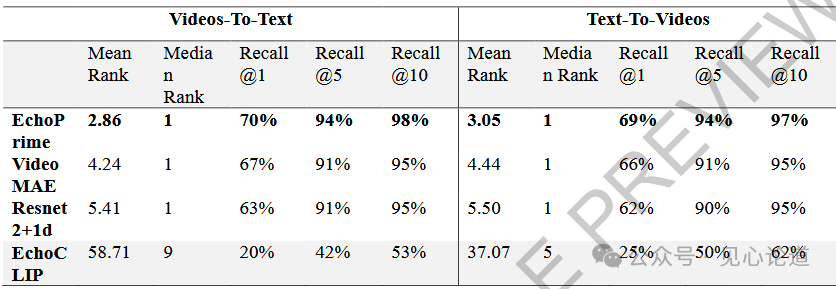
表3:视频-文本报告对测试集的跨模态检索指标。排名越低越好,召回率越高越好。最佳性能以粗体标出。EchoPrime 与在同一数据集上训练的 413 种不同视频编码器(VideoMAE 和 ResNet2+1D)进行了比较。

图1:EchoPrime 概览。(A)训练数据集特征。(B)视频编码器与文本编码器通过对比学习被联合训练,以将超声视频与对应文本报告映射至统一的潜在空间。视图分类器与基于多实例学习的解剖注意力模块则独立训练,用于根据心脏解剖结构对不同切面进行权重分配。(C)推理流程:当输入一项完整的超声心动图检查时,EchoPrime 首先自动识别每段视频的标准切面视角,继而利用视频-文本联合潜在空间中的对比编码器执行检索增强式解读,并通过解剖注意力机制对各视频片段的解读结果进行加权融合,最终生成针对每个心脏结构的研究级综合评估。
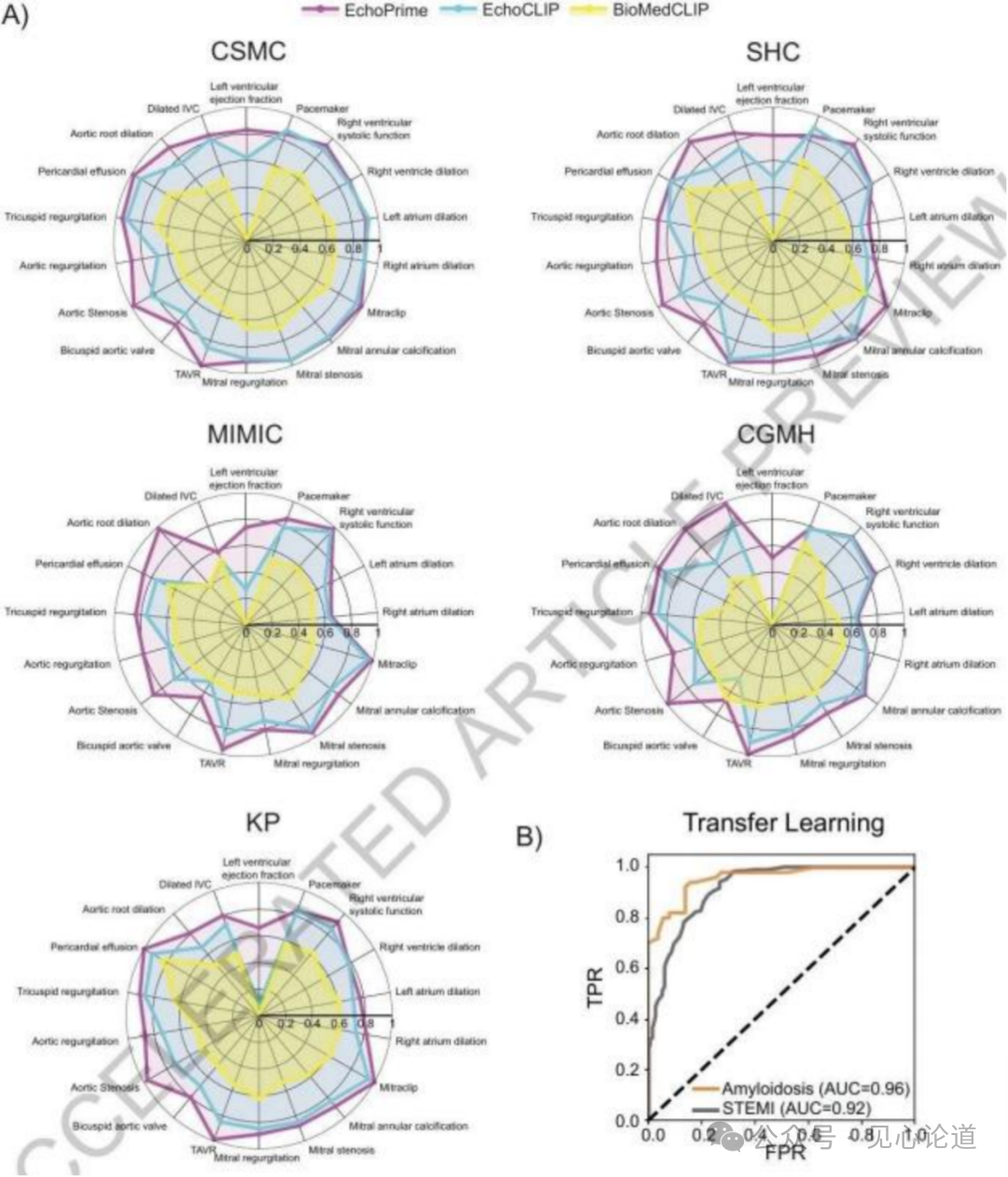
图2:超声心动图预测任务的性能评估。(A)在来自五个不同临床中心的队列数据上,EchoPrime、EchoCLIP 与 BioMedCLIP 在多项超声心动图解读任务中的性能比较。分类任务以AUROC作为评价指标,回归任务则采用R²分数。(B)迁移学习能力验证:通过线性探测策略,EchoPrime 能够准确预测多种多模态心血管疾病,即使这些疾病的标签未在超声心动图报告中显式标注。
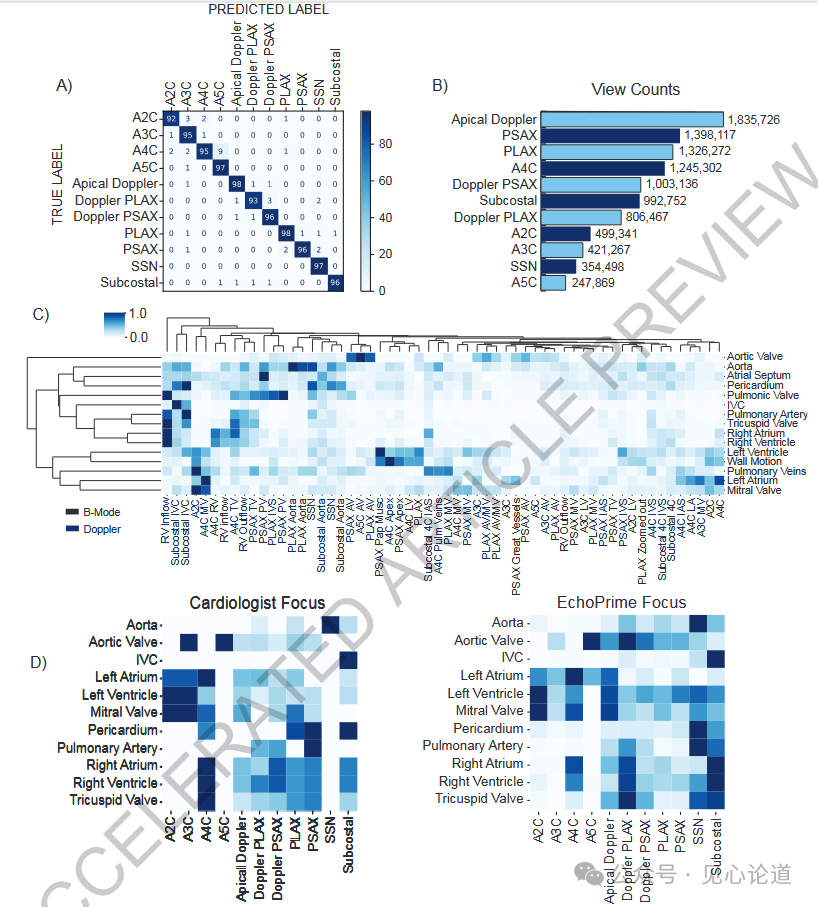
图3:解剖注意力机制在超声心动图研究中对多视频预测结果的加权作用。(A)基于60,000段视频训练的视图分类器,用于识别58种标准超声心动图切面。(B)一次完整的超声心动图检查包含多种不同切面,其分布情况在本研究的训练队列中进行了系统汇总。(C)聚类热图显示了基于学习到的解剖注意力机制,各视频片段针对每个心脏结构的相对优先级与排序结果。(D)心脏病专家(左)与EchoPrime(右)在评估特定解剖结构时对不同切面的优先级分配对比。
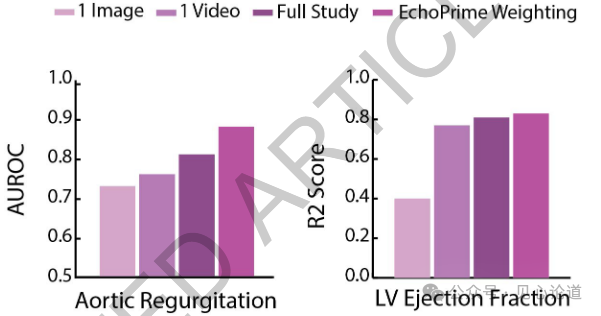
图4:主动脉瓣反流严重程度和左心室射血分数的预测准确性随着输入信息模态的递进而逐步提升:从单张图像,到完整视频;从单个视频,再到整项检查中的多个视频;最终引入解剖注意力机制(EchoPrime加权)后,性能进一步提高。
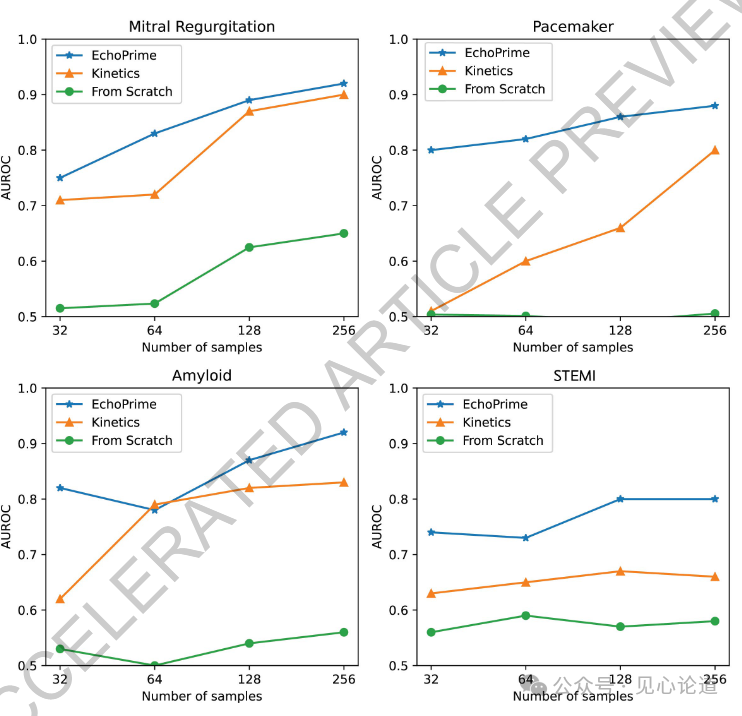
图5:EchoPrime与PanEcho在所有外部验证中心的汇总比较。星号(*)表示经多重性校正后具有统计学意义的差异(p < 0.05/59)。AUC比较采用DeLong检验,MAE和R²指标则使用Bootstrap法进行统计检验。
结 论
本文研究表明,EchoPrime作为首个多视图、视频驱动的超声心动图视觉语言基础模型,成功实现了对全面心脏超声检查的自动化精准评估。通过引入创新的解剖注意力机制,该模型能够智能整合多视图视频信息,在23项核心心脏结构与功能评估任务中展现出卓越性能,其综合表现不仅显著优于现有的专用模型与基础模型,更达到与心脏科医生相当的诊断一致性。该技术突破标志着超声心动图分析正式迈向全自动化时代,为提升临床诊断效率、标准化评估流程及拓展基层医疗可及性提供了切实可行的解决方案。
讨论
EchoPrime——首个基于多视图视频的超声心动图视觉语言基础模型。通过融合超过十年临床数据(训练规模达现有模型10倍以上),该模型创新性地引入解剖注意力机制,实现了多视图视频信息的智能整合与加权评估。在涵盖23项临床任务的系统性验证中,EchoPrime不仅显著超越所有现有基础模型和专用模型,更在四个国际多中心数据集展现出卓越泛化能力。特别值得关注的是,其基于多实例学习构建的视图-解剖结构映射关系,使模型决策过程具有与专科医生相似的逻辑,显著提升了临床可解释性。
尽管本研究存在若干局限(如未纳入频谱多普勒等静态图像、采用回顾性数据验证等),但EchoPrime已展现出变革超声心动图临床实践的潜力:通过实现全面自动化评估,可有效提升诊断效率与一致性,特别在基层医疗和床旁超声场景具有重要应用价值。结合新兴的AI探头导航技术,未来有望实现从图像采集到报告生成的全流程智能化。这项工作标志着心脏超声分析正式迈入多视图视频理解的新纪元,为医学AI与临床工作流的深度整合奠定了坚实基础。